Home
/ How To Calculate Inter Rater Reliability : Interpretation of the icc as an e.
How To Calculate Inter Rater Reliability : Interpretation of the icc as an e.
How To Calculate Inter Rater Reliability : Interpretation of the icc as an e.. Here rows indicates the number of contestants and the columns indicates the number of judges. To calculate the dear for each data element: Determines how consistent are two separate raters of the instrument. Scroll to the middle of the page where it says specify the text file with ratings and click browse. Relations, and a few others.
While there have been a variety of methods to measure interrater reliability, traditionally it was measured as percent agreement, calculated as the number of agreement scores divided by the total number of scores. To calculate the dear for each data element: It gives a score of how much homogeneity, or consensus, there is in the ratings given by judges. To run this analysis in the menus, specify analyze. Percent agreement is 3/5 = 60%.
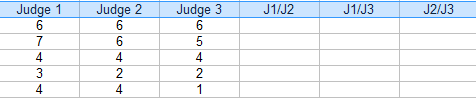
Results Discussion Apa Editing And Defense from image.slidesharecdn.com However, they use different methods to calculate ratios (and account for chance), so should not be directly compared. Divide by the total number of paired records. Head over to the export. Interpretation of the icc as an e. To find percent agreement for two raters, a table (like the one above) is helpful. Percent agreement is 3/5 = 60%. Here rows indicates the number of contestants and the columns indicates the number of judges. Therefore, each encounter has been rated by each evaluator twice.
Convert to a percentage and evaluate the score.
It gives a score of how much homogeneity, or consensus, there is in the ratings given by judges. In this competition, judges agreed on 3 out of 5 scores. There are 10 raters, so fleiss's kappa seems appropriate. The differences in the scores across the task and the raters by using gim and esas were also interpreted through a generalizability study. Convert to a percentage and evaluate the score. A methodologically sound systematic review is characterized by transparency, replicability, and a clear inclusion criterion. Therefore, each encounter has been rated by each evaluator twice. In 1960, jacob cohen critiqued use of percent agreement due to its inability to account for chance agreement. A series of person × rater × task were performed to examine the variation of scores due to potential effects of person, rater, and task after the. Divide by the total number of paired records. The definition of icc in equation 6.8 is a simple example of how we could estimate reliability in a person by rater study design. Select the text document you saved in step 2. How frequently two or more evaluators assign the
With interrater reliability, we incorporate raters into the administration process, and estimate, in different ways, their contribution to the reliability of the entire process. Scroll to the middle of the page where it says specify the text file with ratings and click browse. In 1960, jacob cohen critiqued use of percent agreement due to its inability to account for chance agreement. (versions for 3 or more coders working on nominal data and for any number of coders working on ordinal, interval, and ratio data are also available.) here is a brief feature list: Convert to a percentage and evaluate the score.
Determining Inter Rater Reliability With The Intraclass Correlation Coefficient In Spss Youtube from i.ytimg.com Correlate the test scores of the two tests. I have responses rated on 12 binary categories, treating the categories as separate items on the same measure. (number of times raters disagreed) * ((number of times both raters used the code) + (number of times both raters did not use the code)) / ((number of responses)^2) using the observed and expected agreements, cohen's kappa is then calculated. Determines how compara ble are two different versions of the same measure. (versions for 3 or more coders working on nominal data and for any number of coders working on ordinal, interval, and ratio data are also available.) here is a brief feature list: Scroll to the middle of the page where it says specify the text file with ratings and click browse. To calculate the dear for each data element: Convert to a percentage and evaluate the score.
The definition of icc in equation 6.8 is a simple example of how we could estimate reliability in a person by rater study design.
The differences in the scores across the task and the raters by using gim and esas were also interpreted through a generalizability study. A series of person × rater × task were performed to examine the variation of scores due to potential effects of person, rater, and task after the. Administer the two tests to the same participants within a short period of time. (versions for 3 or more coders working on nominal data and for any number of coders working on ordinal, interval, and ratio data are also available.) here is a brief feature list: In this cohen's kappa calculator just enter the number of rows and columns to enter the ratings. Divide by the total number of paired records. I have responses rated on 12 binary categories, treating the categories as separate items on the same measure. Relations, and a few others. The definition of icc in equation 6.8 is a simple example of how we could estimate reliability in a person by rater study design. These tests are very common in psychology where they are used for having multiple people. There are 10 raters, so fleiss's kappa seems appropriate. How frequently two or more evaluators assign the This is known as percent agreement, which always ranges between 0 and 1 with 0 indicating no agreement between raters and 1 indicating perfect agreement between raters.
Interrater reliability measures the agreement between two or more raters. Here rows indicates the number of contestants and the columns indicates the number of judges. To calculate the dear for each data element: Convert to a percentage and evaluate the score. Divide by the total number of paired records.
Inter Rater Reliability Irr Definition Calculation Statistics How To from www.statisticshowto.com Therefore, each encounter has been rated by each evaluator twice. Crosstabs offers cohen's original kappa measure, which is designed for the case of two raters rating objects on a nominal scale. In 1960, jacob cohen critiqued use of percent agreement due to its inability to account for chance agreement. While there have been a variety of methods to measure interrater reliability, traditionally it was measured as percent agreement, calculated as the number of agreement scores divided by the total number of scores. These tests are very common in psychology where they are used for having multiple people. Convert to a percentage and evaluate the score. To calculate the dear for each data element: Scroll to the middle of the page where it says specify the text file with ratings and click browse.
Interpretation of the icc as an e.
In 1960, jacob cohen critiqued use of percent agreement due to its inability to account for chance agreement. After a specifications manual update 2. However, they use different methods to calculate ratios (and account for chance), so should not be directly compared. Percent agreement is 3/5 = 60%. Recal2 (reliability calculator for 2 coders) is an online utility that computes intercoder/interrater reliability coefficients for nominal data coded by two coders. Correlate the test scores of the two tests. Scroll to the middle of the page where it says specify the text file with ratings and click browse. Crosstabs offers cohen's original kappa measure, which is designed for the case of two raters rating objects on a nominal scale. Therefore, each encounter has been rated by each evaluator twice. To run this analysis in the menus, specify analyze. (number of times raters disagreed) * ((number of times both raters used the code) + (number of times both raters did not use the code)) / ((number of responses)^2) using the observed and expected agreements, cohen's kappa is then calculated. Determines how compara ble are two different versions of the same measure. The differences in the scores across the task and the raters by using gim and esas were also interpreted through a generalizability study.


{kind=link}